

How Dirty Is Your Data?
Is Your Data AI Agent Ready? Or Just a Mess Waiting to Happen...


Is your data dirty? Chances are, yes.
Dirty data is not only a minor inconvenience, it’s a full-blown liability.
Bad data leads to bad decisions.
A brand pours months into a brilliant marketing campaign stunningly creative, perfect timing, precisely segmented audiences, only for a hidden data flaw to derail it. Outdated emails, duplicate records, or missing customer fields quietly chip away at reach, click-throughs, and conversions. Momentum disappears, all that time and effort goes to waste.
It’s not a hypothetical scenario. It's happening right now in organisations across every industry. Think back to the downfall of Pelton, stemming from back-to-back market positioning and sales blunders built upon bad data. Recent research suggests that poor data quality costs the average enterprise over $15 million annually, yet most leaders remain unaware of just how deeply flawed data permeates their operations.
Now, throwing artificial intelligence into the mix: what happens when your data foundation is dirty and flawed? AI becomes risky, misguides strategy, and slows things down.
The Illusion of Good Enough Data
Most organisations are operating under a glaring misconception: that their data is good enough. However, this thinking stems from the fundamental misunderstanding of what good data actually constitutes and how data is used by algorithms.
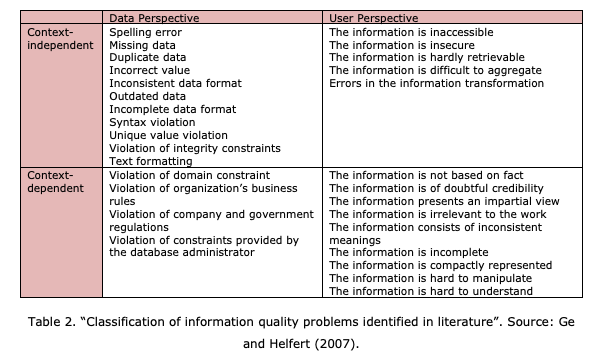
A seemingly minor error, such as a simple spelling mistake or inconsistency in text formatting, can have far-reaching consequences impacting accessibility, completeness, and usability.
When even subtle issues are present, they can cause confusion or misinterpretation, ultimately compromising the overall quality of the data. This diminishes the effectiveness of the collective information, making it incomplete or unreliable. Gaps in data integrity develop into cascading effects, leading to larger gaps in knowledge or erroneous conclusions being drawn from incomplete or flawed data.
Data quality erodes gradually, silently undermining operations until the cumulative impact becomes impossible to ignore, affecting performance and cost.
What Happens When You Introduce AI Agents to Dirty Data?
There’s a lot of talk about agentic capabilities and the next wave of AI, but what is an agent really?
Simply, AI agents are an LLM that’s reading data from your systems and executing actions based on it.
But there’s many problems that can arise, especially when considering dirty data.
A customer with a missing address, an extra zero on the cost of an item, missing rows, inconsistent formatting, all constitute “dirty” data that requires “cleaning’ for proper use. While, “cleaning” data is a fundamental challenge, it's not the only problem…
Imagine a situation where a customer reaches out to your Wifi company’s chatbot, frustrated because their internet connection has suddenly gone down. Naturally, your virtual agent starts by checking the CRM or service records and everything seems fine: the customer’s payments are up to date, the system shows their service as active and fully functional, there are no flagged tickets on their account. From the agent’s limited view, there’s no problem at all.
But here’s the reality: while the system says all is well, a completely different part of your organization is scrambling, a fire has just broken out at a critical intermediate service station. It's affecting connectivity for a whole region, but this hasn’t been flagged or surfaced in a way that your customer-facing systems or agents can see. As a result, the chatbot offers a frustrating, generic answer, or worse, incorrectly tells the customer that there’s nothing wrong.
This is a case of missing context.
The issue isn’t that the information doesn’t exist or is dirty, it's that the agent wasn't given the context to be equipped with the logic or instructions to look for underlying causes beyond the immediate account-level data. In complex environments, where vast amounts of operational, technical, and customer data are scattered across different systems, only knowing what’s in the CRM isn’t enough.
To be effective, an agent must be able to surface the right context at the right moment.
For example, being able to automatically connect the dots that a fire in Service Station A is currently impacting connectivity in Region X, which includes this customer’s location transforms the response from vague or incorrect to accurate and empathetic. Now, the agent can say, Yes, we’re aware of a current disruption in your area due to an incident. Our teams are working on it and expect resolution by ___.
That level of contextual awareness turns a frustrating experience into one where the customer feels heard and informed.
All data is connected. Events are happening every second, everyday, everywhere, and every single one of these events result in downstream consequences and ripple effects.
A fire breaks out in a remote service station. A bridge collapses. A hurricane veers off course, delaying shipments at a port. None of these events happen in isolation. They cascade. They disrupt. They interfere with other systems, often far downstream, and often in ways that aren't immediately obvious.
Whether you're managing a supply chain, handling customer service, making investment decisions, or just trying to assess risk in a volatile world, one thing becomes clear: context matters.
Context-aware systems, with intelligent data integration and proactive surfacing of root-cause signals, are essential for truly effective AI agent support. Understanding the interconnectedness of data is fundamental and requires a massive effort, before we even bring AI into the loop, with the imperative need to understand:
What has happened that affected me in the past?
What can happen today that can be a massive risk for me?
What can I do to mitigate bad outcomes?
And these are all questions that require: good data, context-rich data, and connected data.
Because without connected, contextual, and clean data, even the smartest AI can’t help you make the right decisions, it can only make the wrong ones, faster.
References:
Haug, A., Frederik Zachariassen and Liempd, D. van (2011). The costs of poor data quality. DOAJ (DOAJ: Directory of Open Access Journals). [online] doi:https://doi.org/10.3926/jiem..v4n2.p168-193.
Marsh, R. (2005). Drowning in dirty data? It’s time to sink or swim: A four-stage methodology for total data quality management. Journal of Database Marketing & Customer Strategy Management, [online] 12(2), pp.105–112. doi:https://doi.org/10.1057/palgrave.dbm.3240247.
Mayo, J. (2025). What is ‘dirty’ data and why is it important for businesses to eliminate it? [online] TechRadar. Available at: https://www.techradar.com/pro/what-is-dirty-data-and-why-is-it-important-for-businesses-to-eliminate-it [Accessed 12 Sep. 2025].